
▶️상황
현재 피파 전적검색 앱 프로젝트를 진행 중이다. 사용자가 전적갱신을 하게 되면 다음과 같은 로직으로 진행하게 된다.
- 사용자의 닉네임을 입력받아서 고유한 사용자 식별자(UID)를 가져온다.
- 1번의 UID를 통해 해당 사용자의 매치 리스트를 조회한다.
- 매치 리스트를 가져와서 각 매치에 대한 상세 정보를 요청한다.
이때, 만약 매치가 100개라고 가정했을 때, 3번의 요청이 동기적으로 수행된다면 다음과 같은 일이 발생한다.
- 각각의 요청이 하나씩 순차적으로 처리하게 된다. 즉, 첫 번째 요청이 완료되어야만 두 번째 요청이 시작되고, 두 번째 요청이 완료되어야 세 번째 요청이 시작된다.
- 따라서, 3번째 요청은 1번째 요청이 완료되고 2번째 요청이 진행 중일 때까지 대기하게 된다.
- 이 경우, 전체적으로 매치 리스트를 가져오는 데 시간이 오래 걸리고, 사용자는 요청을 보낸 후 오랜 시간 동안 대기해야 한다.
이러한 동기적인 방식으로 요청을 처리하면 전체적인 성능이 저하될 수 있다. 따라서 비동기적인 방식으로 요청을 처리하는 것이 좋다. 이를 통해 요청을 병렬적으로 처리하여 전체적인 응답 시간을 단축할 수 있다.
▶️@Async
@Async는 Spring AOP에 의해 작동된다. 프록시 패턴 기반이다.
@Async 가 붙은 메소드를 호출하게 되면 스프링이 가로채서 프록시 객체를 생성하게 되고 그 스레드에서 작업을 수행하게 된다.
이렇게 수행하니 private method는 적용할 수 없다. 왜냐하면 스프링이 다른 클래스에서 호출해야 하는데, private 면 호출할 수 없다.
또한 self-invocation 자가 호출의 경우에도 동작하지 않는다. 왜냐하면 프록시 객체를 거치지 않고 직접 method를 호출하기 때문이다.
SimpleAsyncTaskExecutor
Executor를 Bean에서 등록하지 않으면 Spring에서는 AsyncTaskExecutor을 사용해서 알아서 Executor를 등록한다.
많은 블로그에서는 기본으로 SimpleAsyncTaskExecutor 에 의해서 스레드가 관리된다고 한다. 하지만 직접 확인해보니, SimpleAsyncTaskExecutor 에 의해 스레드 관리되는 게 아닌, ThreadPoolTaskExecutor 에 의해 관리된다... 즉, 기본값은 ThreadPoolTaskExecutor 이다.

왜 그런가 봤더니 Spring Boot 에서는 AutoConfiguration 을 통해 ThreadPoolTaskExcutor을 자동으로 등록한다. 많은 블로그에서는 Spring Boot 환경이 아닌 Spring 이어서 그런 것같다.

그래도 SimpleAsyncTaskExecutor에 대해 알아보자면 SimpleAsyncTaskExecutor는 스레드풀 방식이 아니다. 스레드가 필요할 때마다 생성하게 된다. 즉, 재사용을 하지 않기에 자원이 많이 낭비된다.
▶️ThreadPoolTaskExecutor
기본적으로 Spring은 ThreadPoolTaskExecutor 을 사용하지만, 내부 설정 값을 변경할 수 있다.
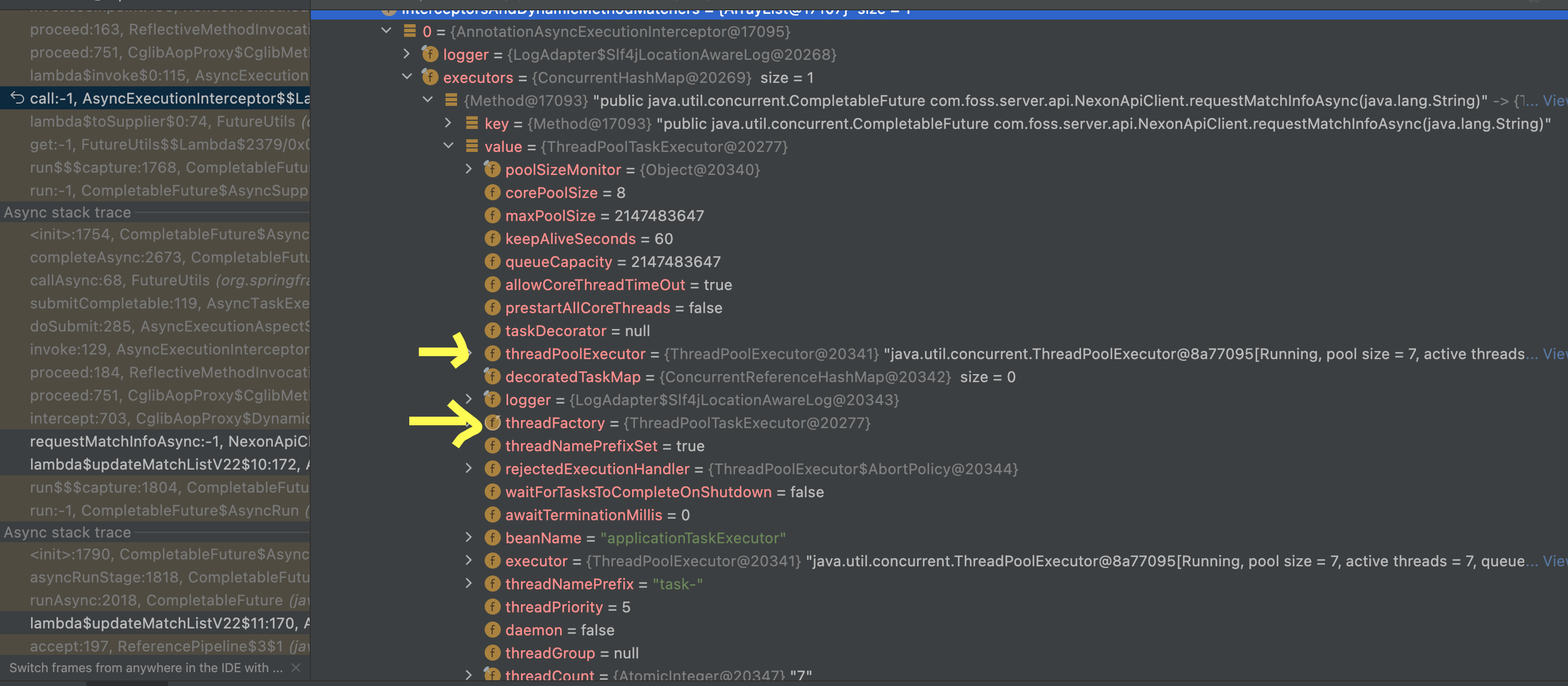
- CorePoolSize : 스레드 풀의 기본 크기이다. 최소 이 만큼 스레드가 유지된다.
- MaxPoolSize : 스레드 풀에서 허용하는 최대 스레드 수이다.
- QueueCapacity : 작업 대기 큐의 용량이다. CorePoolSize 를 초과해서 스레드 생성 요청 시 해당 요청을 Queue에 저장한다. 이때 최대 수용 가능한 Queue의 수이다.
- ThreadNamePrefix : 생성되는 Thread 접두사 지정
▶️ThreadPoolTaskExecutor 동작 방식
- 스레드풀에 작업을 등록하면, 스레드풀에 CorePoolSize 만큼의 스레드가 존재하는지 확인한다.
- 스레드에 작업을 할당한다.
- 스레드풀의 스레드 개수가 CorePoolSize보다 작으면, 스레드풀에 새로운 스레드를 생성하고 작업을 할당하지만, 초과하면 Queue에 추가한다.
- Queue 가 가득 찬 경우, 현재 스레드풀의 스레드 수가 MaxPoolSize 보다 적으면 새로운 스레드를 생성하여 작업을 추가한다.
스레드 풀의 스레드 수가 MaxPoolSize 에 도달한 경우, 새로운 작업 요청이 들어오면 TaskRejectedException 이 발생하게 된다. - 작업 중인 스레드가 할 일을 다하면 Queue에 대기 중인 작업이 있는지 확인하고, 있으면 작업을 가져와서 수행한다. 없으면 해당 스레드는 대기 상태로 돌아간다.
- 스레드풀의 스레드 개수가 CorePoolSize보다 크면 keepAliveTime이 지나고 해당 스레드는 스레드풀에서 제거된다.
▶적용
아래처럼 @Async 만 붙여주면 된다.

결과

▶주의 사항
@Async 와 @Transactional을 같이 사용할 때는 주의가 필요하다. @Async 어노테이션이 붙은 메서드는 호출한 메서드와 독립적인 스레드에서 동작하기 때문에, 비동기 메서드 내에서 생성된 트랜잭션은 호출한 메서드의 트랜잭션과는 독립적으로 동작한다.
즉, 비동기 메서드 내에서 예외가 발생하여 트랜잭션이 롤백되어야 하지만, 다른 스레드에서 독립적으로 처리하므로 원래의 호출 메서드의 트랜잭션에 영향을 미치지 않는다.
▶마무리
@Async , ThreadPoolTaskExecutor 에 대해서 알게 되었다. 참고로 ThreadPoolExecutor 랑 ThreadPoolTaskExecutor의 차이는 ThredPoolExecutor는 Java 패키지에 있고 ThreadPoolTaskExecutor는 Spring 패키지에 있다. 결국에 Spring이 ThreadPoolExecutor를 쉽게 사용하게 만들어 준 것이다.
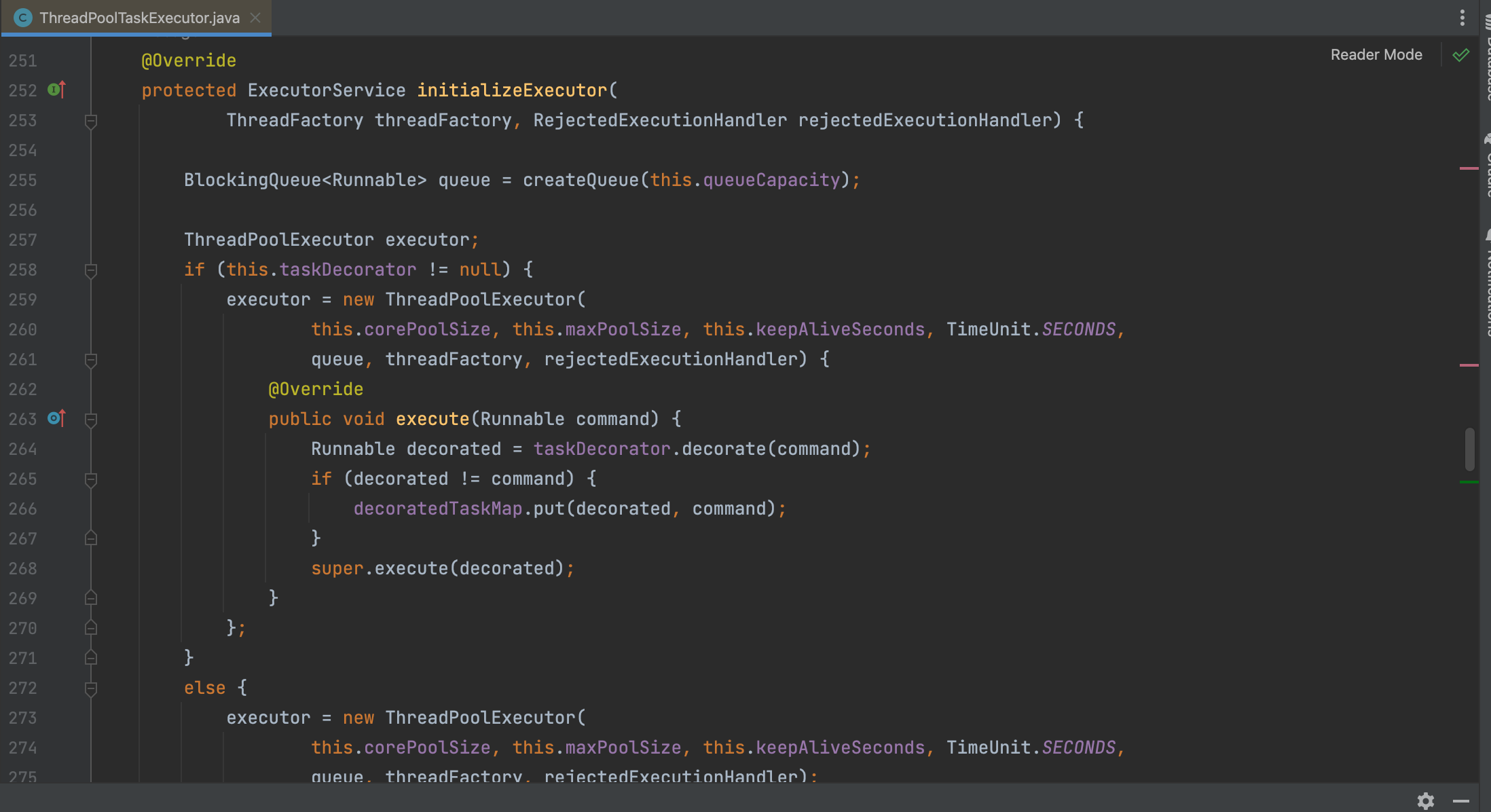
가장 많은 고민을 하는 것은 CorePoolSize 와 MaxPoolSize , QueueCapacity 를 어떻게 설정해야 할지 모르겠다.
적정 스레드 풀 개수 = CPU 수 * (CPU 목표 사용량) * (1+대기 시간/서비스 시간) 이것으로 CorePollSize 를 잡고... QueueCapacity 는 최댓값으로 설정할지 아니면 큐 사이즈를 낮게하고 MaxPoolSize 를 크게 할 지 고민이다.
전자로 하면 트래픽이 몰릴 때 너무 느리고, 후자로 하면 리소스 낭비로 이어질 가능성이 크다. 모니터링을 통해 적절한 값을 찾아봐야겠다.
'개발 이야기 > Spring' 카테고리의 다른 글
| Spring WebClient 적용기 (1) | 2024.04.26 |
|---|---|
| Spring paging count query 조건 (0) | 2024.03.29 |
| ResponseEntityExceptionHandler 사용하는 이유 (1) | 2024.03.15 |
| Spring Profile 개발 서버와 운영 서버 분리, Environment Configurations (0) | 2024.02.03 |